手机版 欢迎访问人人都是自媒体网站

不少时候,一篇文章能否得到广泛的传播,除了文章本身实打实的质量以外,一个好的标题也至关重要。本文爬取了虎嗅网建站至今共 5 万条新闻标题内容,助你找到起文章标题的技巧与灵感。同时,分享一些值得关注的文章和作者。

写在前面:由于文中有一些超链接,无法在公众号打开,建议点击底部「阅读原文」或者复制下面的博客链接到浏览器打开,体验更好。https://www.makcyun.top/
一. 分析背景 1.1 为什么选择「虎嗅」在众多新媒体网站中,「虎嗅」网的文章内容和质量还算不错。在「新榜」科技类公众号排名中,它位居榜单第 3 名,还是比较受欢迎的。所以选择爬取该网站的文章信息,顺便从中了解一下这几年科技互联网都出现了哪些热点信息。
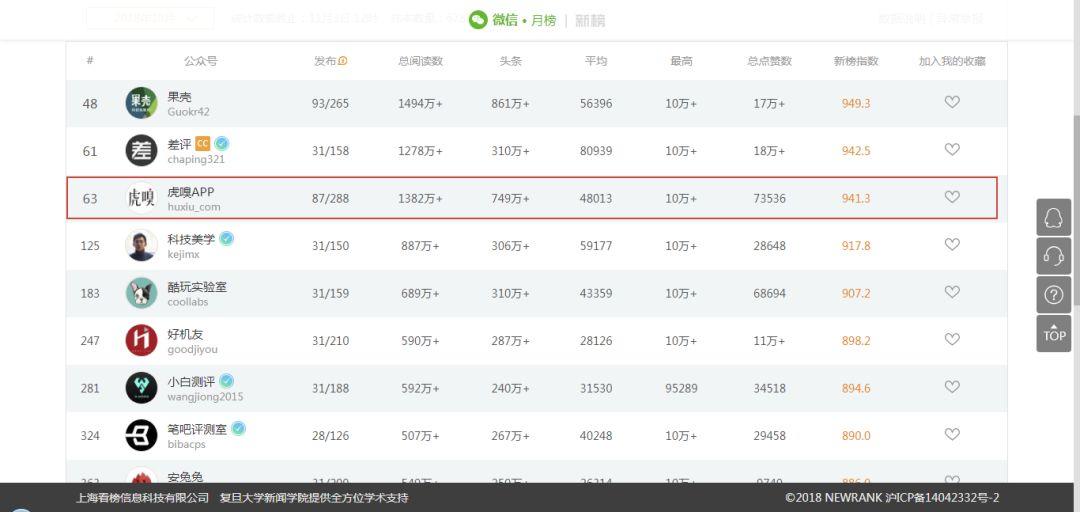
「关于虎嗅」虎嗅网创办于 2012 年 5 月,是一个聚合优质创新信息与人群的新媒体平台。该平台专注于贡献原创、深度、犀利优质的商业资讯,围绕创新创业的观点进行剖析与交流。虎嗅网的核心,是关注互联网及传统产业的融合、明星公司的起落轨迹、产业潮汐的动力与趋势。
1.2 分析内容分析虎嗅网 5 万篇文章的基本情况,包括收藏数、评论数等;
发掘最受欢迎和最不受欢迎的文章及作者;
分析文章标题形式(长度、句式)与受欢迎程度之间的关系;
展现近些年科技互联网行业的热门词汇。
1.3 分析工具Python 3.6
pyspider
MongoDB
Matplotlib
WordCloud
Jieba
2. 数据抓取使用 pyspider 抓取了虎嗅网的主页文章,文章抓取时期为 2012 年建站至 2018 年 11 月 1 日,共计约 5 万篇文章。抓取 了 7 个字段信息:文章标题、作者、发文时间、评论数、收藏数、摘要和文章链接。
2.1 目标网站分析这是要爬取的 网页界面,可以看到是通过 AJAX 加载的。
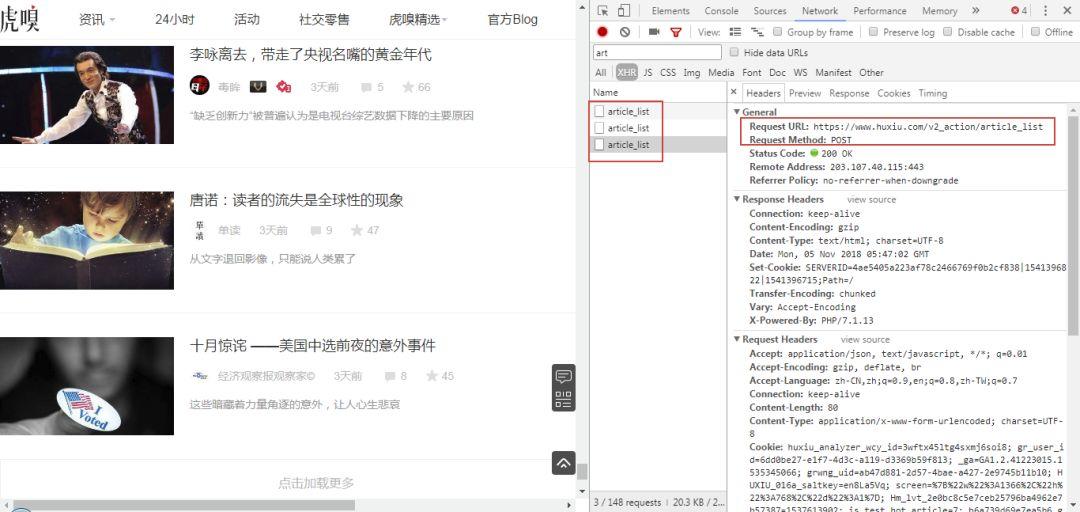
右键打开开发者工具查看翻页规律,可以看到 URL 请求是 POST 类型,下拉到底部查看 Form Data,表单需提交参数只有 3 项。经尝试, 只提交 page 参数就能成功获取页面的信息,其他两项参数无关紧要,所以构造分页爬取非常简单。
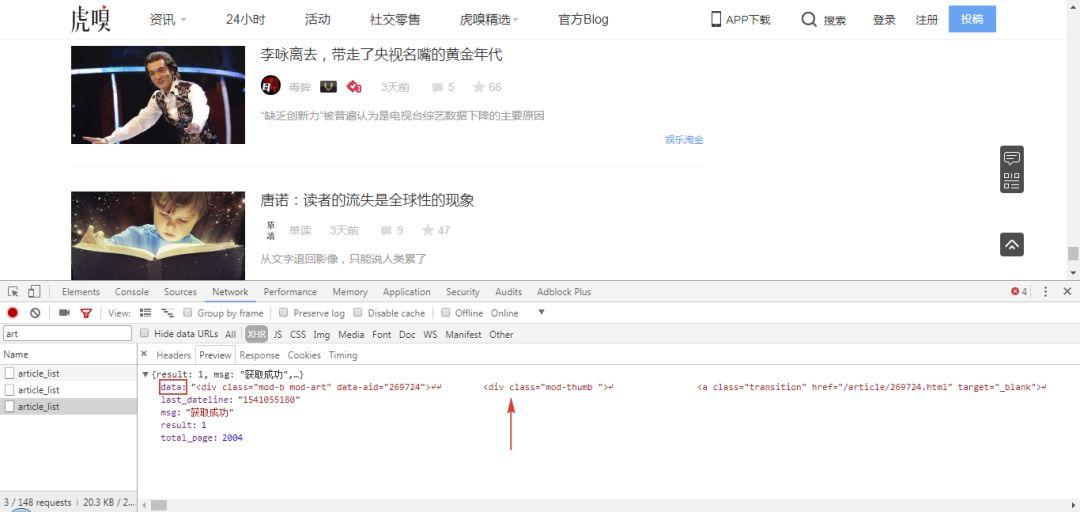
接着,切换选项卡到 Preview 和 Response 查看网页内容,可以看到数据都位于 data 字段里。total_page 为 2004,表示一共有 2004 页的文章内容,每一页有 25 篇文章,总共约 5 万篇,也就是我们要爬取的数量。
以上,我们就找到了所需内容,接下来可以开始构造爬虫,整个爬取思路比较简单。之前我们也练习过这一类 Ajax 文章的爬取,可以参考:
做 PPT 没灵感?澎湃网 1500 期信息图送给你
2.2 pyspider 介绍和之前文章不同的是,这里我们使用一种新的工具来进行爬取,叫做:pyspider 框架。由国人 binux 大神开发,GitHub Star 数超过 12 K,足以证明它的知名度。可以说,学习爬虫不能不会使用这个框架。
网上关于这个框架的介绍和实操案例非常多,这里仅简单介绍一下。
我们之前的爬虫都是在 Sublime 、PyCharm 这种 IDE 窗口中执行的,整个爬取过程可以说是处在黑箱中,内部运行的些细节并不太清楚。而 pyspider 一大亮点就在于提供了一个可视化的 WebUI 界面,能够清楚地查看爬虫的运行情况。
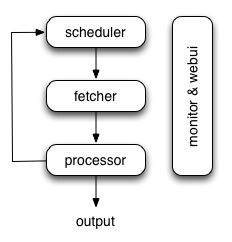
pyspider 的架构主要分为 Scheduler(调度器)、Fetcher(抓取器)、Processer(处理器)三个部分。Monitor(监控器)对整个爬取过程进行监控,Result Worker(结果处理器)处理最后抓取的结果。
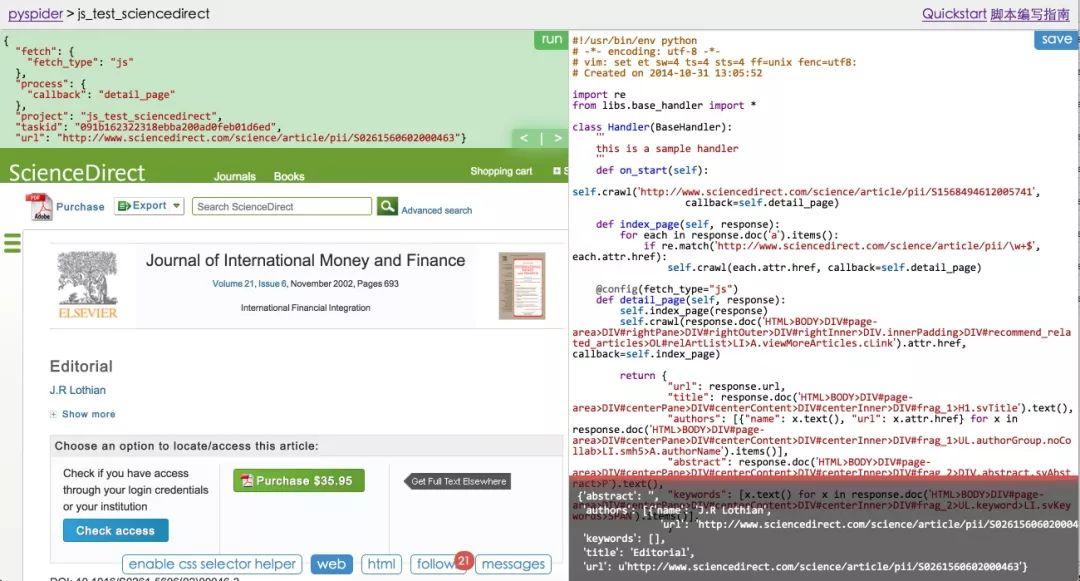
该框架比较容易上手,网页右边是代码区,先定义类(Class)然后在里面添加爬虫的各种方法(也可以称为函数),运行的过程会在左上方显示,左下方则是输出结果的区域。
这里,分享几个不错的教程以供参考:
官方主页:
pyspider 爬虫原理剖析:
pyspider 爬淘宝图案例实操:https://cuiqingcai.com/2652.html
安装好该框架并大概了解用法后,下面我们可以就开始爬取了。
2.3 抓取数据CMD 命令窗口执行:pyspider all 命令,然后浏览器输入::5000/ 就可以启动 pyspider 。
Copyright © 2018 DEDE97. 织梦97 版权所有 京ICP




 这篇文章把数据讲透了(五):数据可视化(上)
这篇文章把数据讲透了(五):数据可视化(上) 数据驱动决策的10种思维
数据驱动决策的10种思维 数据的比较分析(三):假设性检验在数据比较分析中的应用
数据的比较分析(三):假设性检验在数据比较分析中的应用 技多不压身 | 产品经理需知的那些数据库基础知识
技多不压身 | 产品经理需知的那些数据库基础知识 人机耦合时代下的数据众包产业化
人机耦合时代下的数据众包产业化 2019中国网络视频市场年度分析
2019中国网络视频市场年度分析