手机版 欢迎访问人人都是自媒体网站

网络数据是沙地,数据分析的作用就是在一堆冗杂无序的沙地中找出产品有用的“金子”。
数据——可以简单理解为人们动作行为的符号表示。信息技术的发展,使得计算机每时每刻记录着人们的数据,人们在计算机面前,早已经是“透明人”。
万物皆在运动,对于数据来说,也是一直在变化的。我们对数据进行分析,就是希望可以从不断变化的数据中发现规律、发现趋势,提炼有价值的内容。
好的数据是一座未被发掘的金矿,而好的数据分析报告,可以帮助经营管理者明确战略,不断优化和调整策略,也可以帮助产品经理更好地掌握产品运行情况,不断有针对性的升级优化产品,提升客户体验,增强用户粘性,确保产品用户和效益持续增长。
02 分析目的不同领域有不同领域的分析目的。例如基金公司的数据分析,更多的是来对所投资股票的价值分析。电商公司的数据分析,会很关注漏斗的转化率。结合本文的实际案例分析,我们数据分析的目的,主要有以下几点:
验证我们的判断。例如:我们根据经验,判断一般晚上探索某个领域的知识会比较多,我们来验证自己的判断是否正确。
用户兴趣发现以及商机发现。例如:某个关键词检索很频繁,说明极有可能成为热点,提早进行针对于热点的准备,从而获得流量优势。
防范风险。例如:某个关键词在某个地区短时间内频率很高,那极有可能会存在区域风险。相关部门或企业,提早进行介入处置,化解风险,从而尽可能减少损失。
03 数据准备既然是实践,就需要对真实的数据进行分析。
本文数据来自于搜狗实验室《搜索引擎用户查询日志(SogouQ)》(数据地址:)。使用的搜狗实验室所提供的精简版数据,此数据包包含一天的检索数据,数据压缩包小为63MB,解压后数据包大小为144MB。
数据格式为:访问时间\t用户ID\t[查询词]\t该URL在返回结果中的排名\t用户点击的顺序号\t用户点击的URL。
其中,用户ID是根据用户使用浏览器访问搜索引擎时的Cookie信息自动赋值,即同一次使用浏览器输入的不同查询对应同一个用户ID。
数据样例如下:
00:00:00 2982199073774412 [360安全卫士] 8 3 download.it.com.cn/softweb/software/firewall/antivirus/20067/17938.html
在此主要是给大家形象地展示一下数据格式,更为详细的数据大家可以去搜狗实验室官网获得。
04 分析过程 1. 不同时段的检索情况我们以小时为单位,共分24小时,来查看全天时段的用户检索情况。首先在Python程序中导入CSV文件,这个太基础了,就不在此多讲了。
由于源数据时间格式是“时:分:秒”格式,而我们是准备以每一小时为时段进行分析。为了便于操作,我们将源数据“时:分:秒”处理为仅保留小时。之后我们将数据格式化成DataFrame数据格式。使用groupby函数,对时间进行操作。使用size()对分组数据进行归集显示。
由于本文主要讲解思路,在此仅展示部分源代码。如果需要操作指点,可以关注我的微信公众号:佳佳原创。在公众号中留言,我看到后,第一时间会回复大家。部分源代码如下:
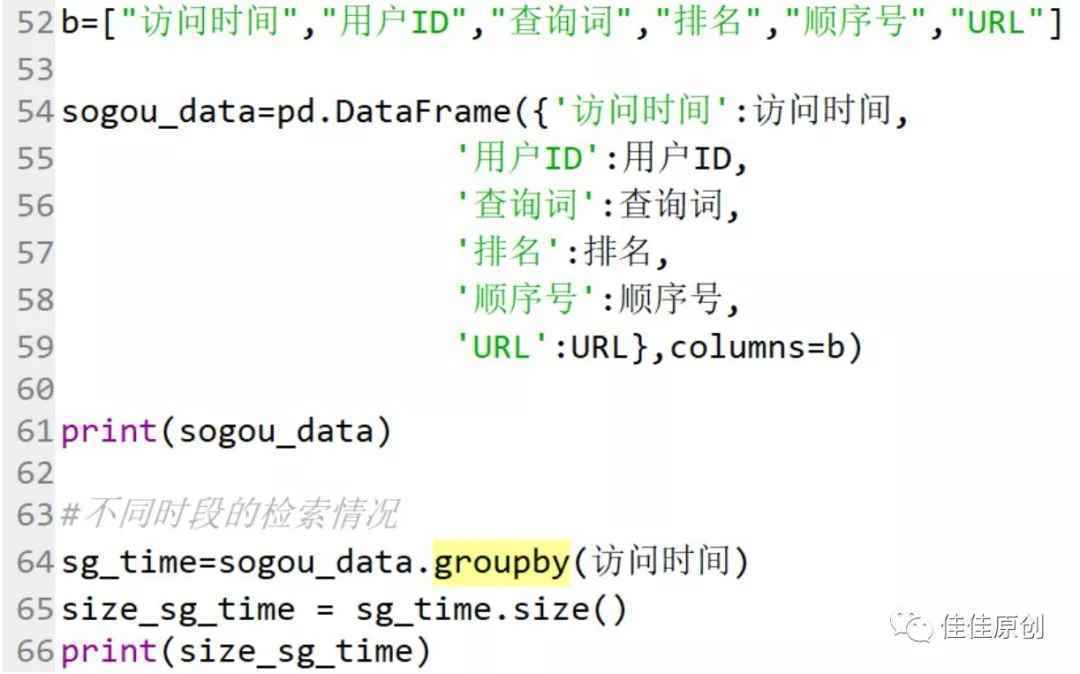
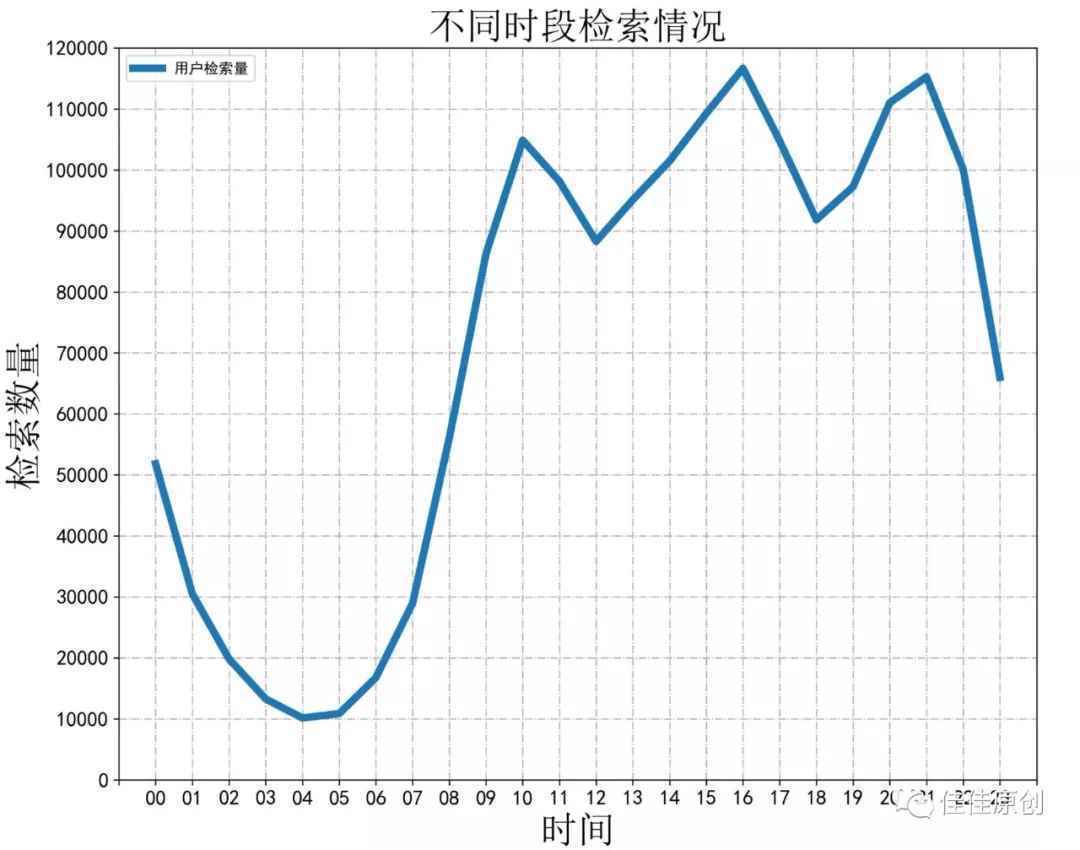
上图中的print( )函数主要用来看生成的数据。注释掉也可以。根据操作,生成相应数据,并根据数据生成分析折线图如下图所示:
如果对于生成折线图有时需要不断微调,而每次生成数据运算时间较长,其实可以将生成的数据先保存起来,之后调整折线图元素的时候,直接使用结果数据就可以,不需要再重新计算数据,这样可以节约很多时间。
经过我们将数据图示化后,原本密密麻麻的数据显得更为清晰,我们可以方便直观地看出,用户在凌晨4点左右检索频次是最少的,而在下午16点左右检索频次最多,也侧面反应出了网民的上网习惯。
如果我们是广告商家,我们可以针对这种情况,对不同时段的广告进行有针对性的定价。而我们如果是需要进行广告投放,也知道哪个时段投放,广告的曝光率相对最高。
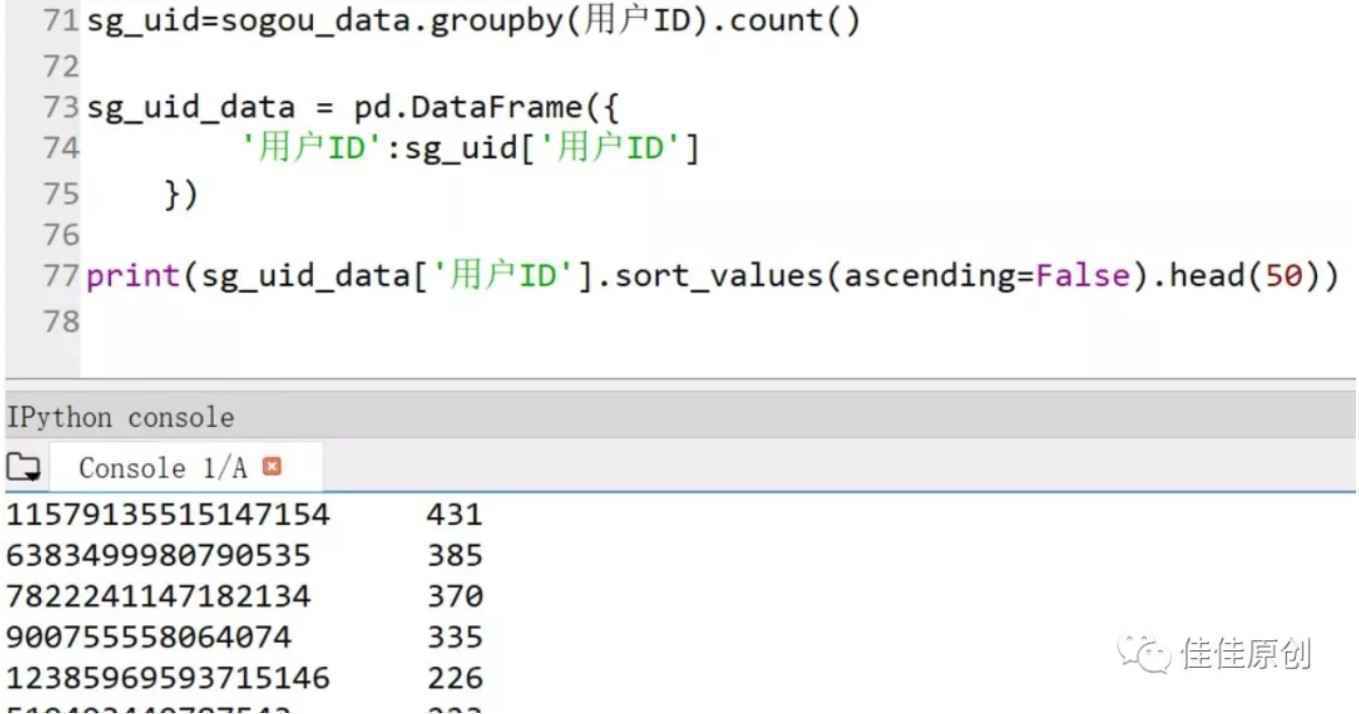
2. 不同用户的检索情况接下来,我们再分析一下不同用户的检索情况,看一看哪些用户检索量比较大。
这个分析需要用到Python DataFrame中的count()操作,即:groupby(用户ID).count()。之后我们将新生成的数据再构建一个DataFrame,取排名前50的用户数据,做降序操作。部分源代码如下图所示:
Copyright © 2018 DEDE97. 织梦97 版权所有 京ICP




 这篇文章把数据讲透了(五):数据可视化(上)
这篇文章把数据讲透了(五):数据可视化(上) 数据驱动决策的10种思维
数据驱动决策的10种思维 数据的比较分析(三):假设性检验在数据比较分析中的应用
数据的比较分析(三):假设性检验在数据比较分析中的应用 技多不压身 | 产品经理需知的那些数据库基础知识
技多不压身 | 产品经理需知的那些数据库基础知识 人机耦合时代下的数据众包产业化
人机耦合时代下的数据众包产业化 2019中国网络视频市场年度分析
2019中国网络视频市场年度分析