手机版 欢迎访问人人都是自媒体网站

本文内容来自神策数据《智能推荐——应用场景与技术难点剖析》闭门会分享内容整理,分享者将我们介绍:如何从四个方面做一个推荐系统。

在工作中,大家遇到的与推荐系统相关的问题是:“数据太稀疏、数据没有形成闭环、数据没办法跟其他系统结合”等等。
这些内容是摆在我们面前的实际问题,那么当我们真正要开始做一个推荐系统时,需要从几方面考虑问题呢?
1. 算法:到底应该选择什么样的算法?无论是协同过滤还是其他算法,都要基于自己的业务产品。
2. 数据:当确定了算法时,应该选择什么样的数据?怎样加工数据?用什么样方法采集数据?
有句话叫做“机器学习=模型+数据”,即便拥有了一个很复杂的模型,在数据出现问题的情况下,也无法在推荐系统里面发挥很好的效果。
3. 在线服务:当模型训练完毕,数据准备充分之后,就会面对接收用户请求返回推荐结果的事项,这其中包含两个问题:
(1)返回响应要足够迅速,如果当一个用户请求后的一秒钟才返回推荐结果,用户很可能因丧失耐心而流失;
(2)如何让推荐系统具有高可扩展性。当 DAU 从最初的十万涨到一二百万时,推荐系统还能像最初那样很好地挡住大体量的请求吗?这都是在线服务方面需要考虑和面临的问题。
4. 评估效果:做好上述三点,并不代表万事大吉。
一方面,我们要持续迭代推荐算法模型与结构;另一方面要去构建一套比较完整、系统的评价体系和评估方法,去分析推荐效果的现状以及后续的发展。
我会从以上四个方面,跟大家分享一下我们在实际情况中遇到的一些问题以及总结出的解决方法。
一、算法在各种算法中,大家最容易想到的就是一种基于标签的方法。
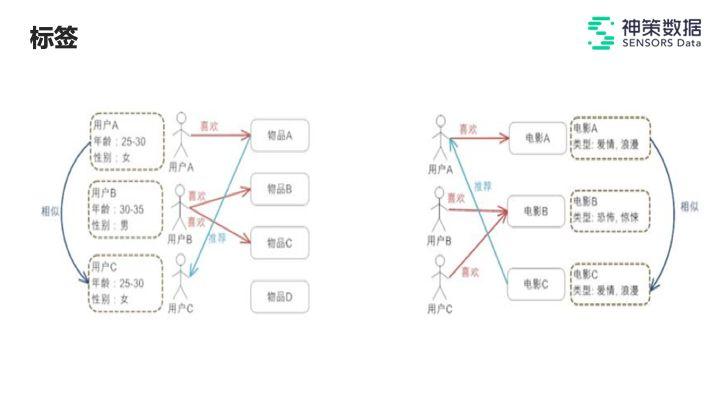
如上图所示,标签可分为两种:
1. 用户标签:
假设我们拥有一部分用户标签,知道每一个用户的年龄、性别等信息,当某类年龄和某种性别的用户喜欢过某一个物品时,我们就可以把该物品推荐给具有同样年龄、性别等用户标签的其他用户。
2. 内容标签:
与用户标签的思路相似,如果用户喜欢过带有内容标签的物品,我们就可以为他推荐具有同样标签的内容。
但很明显,这种基于标签的方法有一个重要的缺点——它需要足够丰富的标签。也许在多产品中,可能并没有标签或者标签数量非常稀疏,所以标签的方法显然不足以应对。
另外,协同过滤也是一种非常经典、被较多人提及的一种方法,是一种常见且有效的思路。
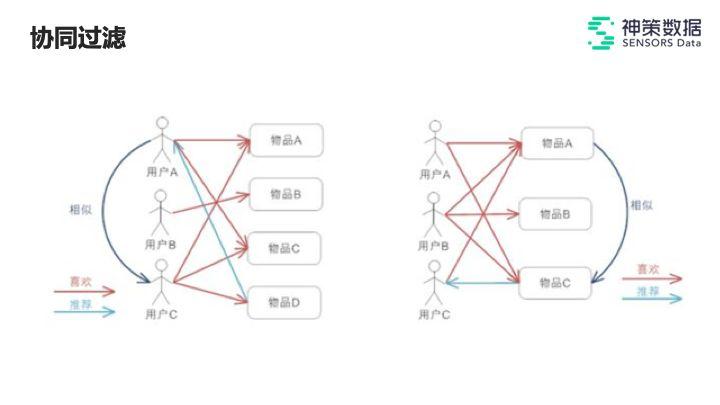
随着技术的不断发展,基本从 2012 年以后,深度学习几乎被整个机器学习界进行反复的讨论和研究。
谷歌在 2016 年提出一套基于深度学习的推荐模型,用深度学习去解决推荐的问题,利用用户的行为数据去构建推荐算法。
1. 深度学习的目的之一:向量化推荐系统其实是在做一个关于“匹配”的事情,把人和物做匹配。
看似很难的推荐系统,其实也有简单的思路——做人和物的匹配,把该用户可能感兴趣的物品推荐给他(她)。
如果站在数学的角度去思考这个问题,我们如何去计算人和物的相似度匹配呢?
在推荐领域,深度学习的目的之一就是尝试将人和物向量化,即把某个人和某个物品学习成一种统一的表示方式,随后在这个统一的表示方式中计算这个人和物品的相似度,当人和物都映射到同一个可比较的空间中时,就能够基于计算结果去执行相关的内容推荐。
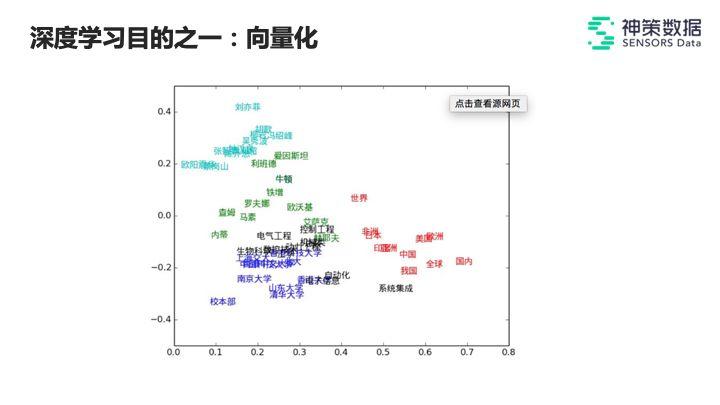
把最终的结果映射到这张二维的平面图表里,用户认为相似的内容就会映射在向量上。当拥有内容向量之后,之后再将用户映射进来即可。
比如:用户到达了上图某个地方,根据他所处的位置,可以向其推送教育、娱乐、科学、地理等内容。
讲到这里,有些朋友就会提出疑问:既然深度学习如此复杂,那在实践中究竟有没有作用?
其实,站在实战经验的角度来看,当具备一定的数据量时,会带来比较明显的效果提升。但当你要去搭建一个深度学习模型的时候,可能真的会遇到很多问题。
比如:用多少数据量去训练模型是可以的?训练数据该用什么格式?多“深”才算深度模型?训练模型太慢了怎么办等。
这些关于在搭建深度学习模型时遇到的困难与解决方法,会在以后跟大家分享。
2. 冷启动冷启动是算法部分经常遇到的问题。
在冷启动阶段,数据比较稀疏,很难利用用户的行为数据实现个性化推荐。
冷启动的问题分为两种:新内容的冷启动、新用户的冷启动。
接下来,我们分享一下新内容的冷启动要如何实现:
举个例子:
资讯场景的需求往往是将发布的新内容(如 10 分钟内发布的内容),以实时且个性化的方式分发到用户的推荐结果中去。
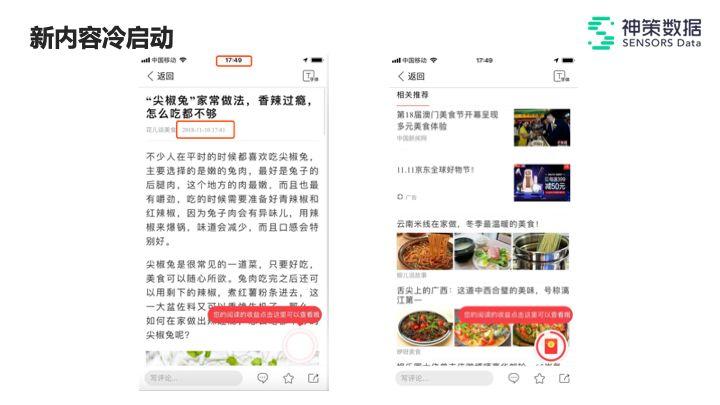
上图这篇文章在 17:41 发出,那么就需要在极短的时间内根据这篇文章的内容去做一些个性化的相关推荐。
此文内容围绕美食展开,用户点开这篇文章之后,文章的相关推荐里面就要有跟美食相关的一些内容。
Copyright © 2018 DEDE97. 织梦97 版权所有 京ICP




 这篇文章把数据讲透了(五):数据可视化(上)
这篇文章把数据讲透了(五):数据可视化(上) 数据驱动决策的10种思维
数据驱动决策的10种思维 数据的比较分析(三):假设性检验在数据比较分析中的应用
数据的比较分析(三):假设性检验在数据比较分析中的应用 技多不压身 | 产品经理需知的那些数据库基础知识
技多不压身 | 产品经理需知的那些数据库基础知识 人机耦合时代下的数据众包产业化
人机耦合时代下的数据众包产业化 2019中国网络视频市场年度分析
2019中国网络视频市场年度分析