手机版 欢迎访问人人都是自媒体网站

看见别人看不见的价值,用图表武装思想。

使用上篇讲述的常规的数据分析手段,能够帮助我们快速对数据进行规整和剖析,进而总结出数字反映的客观事实。我们常提到的数据统计及分析工作,大部分止步于此。
然而是否有可能对数据进行更深层次的挖掘,去寻找一些不那么显著可见的事实背后隐藏的规律,甚至是一些猜想呢?
答案是肯定的。
为了达成该目的,我们需要借助一系列机器学习的算法,这也是本篇的重点内容之一。
 - 数据挖掘及表达进阶")
在完成全部分析形成结论后,若要精益求精就无法绕过最终的图表美化工作,即数据可视化,良好的表达呈现有助于观众更好的理解你的观点。
产品需要考虑表现层的用户体验,数据报告亦是如此。
因此,本文最后的篇幅会留给数据可视化。
回顾一下数据分析的5个步骤:
明确目标;
数据预处理;
特征分析;
算法建模;
数据表达。
上篇《极简数据分析(上) – 10分钟掌握关键数据分析方法》介绍了前3步,本篇开始进入到最后2个步骤。
算法建模不少非技术出身的同学一听到算法建模、机器学习、大数据、人工智能等概念,就开始头大,实际上大可不必。
本文其实也是定位面向于非技术人员的,因此首先可能需要对相关的技术进行去魅。
什么是算法?
可以理解成算法是计算的方法或技巧,通过合适的算法对原始数据进行加工以得出结论,是我们解决问题的核心思路。
什么是数据挖掘?
顾名思义,是对并非浮于表面的信息进行深度研究,可能是可观察到的事实背后的规律或原因,也是我们想获取的知识。
什么是机器学习?
其目的是让机器可以通过学习,自主去解决问题,而并非执行一段代码内既定的任务。
而人工智能可能是最后我们追求的美好结果,不论是数据挖掘还是机器学习,都是在实现人工智能过程中的手段,虽然其实离真正的智能还相差甚远。
所以在数据分析范畴内对相关技术的应用,我们可以描述为:利用机器学习的相关算法进行数据挖掘,寻找数据事实背后的规律。
一个好消息是:算法在人工智能技术和高级语言经历了多年发展至今后,很多已经被封装成了独立的函数或类,可以直接调用,不少开发框架内也已经集成了大量的库或包,大大降低了机器学习的技术门槛,也因此让我们利用相关技术进行数据分析成为了可能。
机器学习主要分为监督学习和非监督学习,此外还有强化学习。
这里主要介绍监督学习和非监督学习。两者的区别主要在于是否有已知的训练集,即监督学习类似教学,告诉机器一些已经确定的输入条件(特征值)和输出结果(标签),然后由机器总结规律再运用到新样本中。而非监督学习类似自学,机器需要自己从全部样本中总结规律。
在数据分析过程中,根据分析目的和数据特征的不同,通常会进行3类分析:回归、分类、聚类。在每类分析中还包含了多种模型,接下来我们会介绍其中常用且有代表性的模型和实现方式。
1. 线性回归线性回归可能是大家平时听到最多的模型了,其通常被应用在对连续变量的预测中。
线性回归会尝试在一些已知的自变量和因变量之间寻找到一种关系,通过拟合出最佳的回归线去表达这种关系,进而可以预测在回归线上其他点的数据。如根据下面左图的已知数据,拟合出右图的直线函数。
 - 数据挖掘及表达进阶")
在Python中可直接调用sklearn库中的相关模型实现,简单的一元线性回归实例如下,多元线性回归的实现类似,但会有多个自变量,即输出的斜率值会有多个。
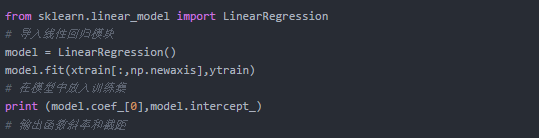
既然该模型是基于已知数据拟合得出的,就可能存在过拟合或欠拟合的可能,不论哪种都会使模型失去泛化的能力,很难去进行预测。
造成问题的最常见原因可能是训练样本量太少或者样本的维度太少。
Copyright © 2018 DEDE97. 织梦97 版权所有 京ICP




 这篇文章把数据讲透了(五):数据可视化(上)
这篇文章把数据讲透了(五):数据可视化(上) 数据驱动决策的10种思维
数据驱动决策的10种思维 数据的比较分析(三):假设性检验在数据比较分析中的应用
数据的比较分析(三):假设性检验在数据比较分析中的应用 技多不压身 | 产品经理需知的那些数据库基础知识
技多不压身 | 产品经理需知的那些数据库基础知识 人机耦合时代下的数据众包产业化
人机耦合时代下的数据众包产业化 2019中国网络视频市场年度分析
2019中国网络视频市场年度分析