手机版 欢迎访问人人都是自媒体网站

作为一个产品新人,我自认为自己的数据敏感程度高于同等经验的人群。看过上一篇文章的人也应该知道这一点,指路–>《luckin:优惠券获客可以走多远?》
那么我今天就想跟大家分享一下我对数据的看法,主要从三个维度:
辨别数据
收集数据
处理数据
数据具有欺骗性数据具有欺骗性,这也是总所皆知的事情了,但是越是普遍存在的人们却往往会忽视。下面就看一个数据诈骗的案例。
luckin在融资的时候,列举出了这样的一系列的数据:
从整体市场空间看,目前全球咖啡消费市场规模约12万亿元,其中中国仅2000亿元左右,提升的空间仍非常巨大。
或许但从市场来看中国的咖啡市场的确是一片蓝海,市场极具发展优势,但是20000元背后意味着什么呢?
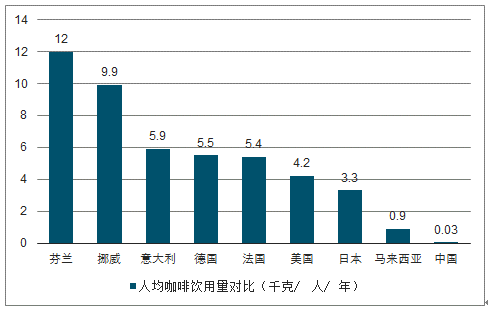
没错,就是中国人的消费习惯,在自古以来信仰茶文化的中国,对咖啡并没有如此感冒,大量的人根本没有饮用咖啡的习惯。
这就跟在美国推销猪肉一个道理,有潜在空间,可是人家压根就不买账。
当然数据具有欺骗性的例子还太多了:
一个篮球运动员想要投篮命中率达到百分之八十,只需要他投中一个三分,以后再也不投就好了。
一个医院想要抢救死亡率维持在百分之0,他只需要不接受濒危的病人就好了。
这些看上去很光鲜亮丽的数据,其实不能反映生活中的真实情况……
所以我们如何去辨别数据呢?
反向推导法:从数据的结果追寻数据来源,比如说,中国的咖啡市场有2000亿,这是一个结果性的数据,这个结果是如何导致的呢?我们自然就会反推到,中国的咖啡消费能力,再后再推到中国人的饮用习惯。
反证法:找出反向数据来对比当前数据,比如,中国2000亿的咖啡市场对应中国咖啡市场潜力十足,但是目前中国咖啡竞争——星巴克,太平洋咖啡……竞争十分激烈。然后再分析,这些咖啡的增长速度,我们可以发现巨头星巴克的销售额是下降的。
识别数据不要要我们一味地去否定数据,而是找准数据的方向,比如有一个优惠券的任务下来了,我们要进行相关的数据处理,一般人可能会对比之前的优惠券政策进行相应处理、逻辑优化啊。再进一步可能是针对用户从时间,进行处理。
但其实我们也是被数据欺骗了,那么该如何收集数据呢?我们接着看:
收集数据数据具有欺骗性,我们拥有了识别数据的能力这个时候就可以开始着手进行收集数据收集了,收集数据也是十分讲究的。
任何事情确定方向很重要,数据收集当然也一样,那么该如何确定方向呢?
当然是第一性原理,也就是探寻物质的本质。
比如有一个优惠券的任务,这个时候要收集相关数据、开始分解了,优惠券——用户、商家。即用户使用优惠券、商家收益,这个时候数据就显而易见了——使用频率以及收益。
但是单有两个数据是完全不够的,我们还需要更多数据,这里我平时会用的一种方法就是闭环因果法。
比如我看到数据方向里有收益,我的逻辑思路是这样的:
收益-收入-成本-用户消费-收入-收益
使用频率-消费习惯-消费能力-物价-优惠券种类-使用频率
然后可用数据就多了,每一环都可以对应好多数据,这个时候就要对数据进行处理啦。
这个时候并不是所有数据都是我们想要的,这个时候就要用上奥卡姆剃刀定律了,排在我们前面的是一个优惠券问题,得到了一堆相关的数据,但是最简单直接,可以为证的数据是什么呢?
收益-交易流水
使用频率-优惠券种类(折数)
当然我们筛选出的是主要数据,其他的一些数据不是不看了,而是辅助,选定核心数据然后进行数据的对比分析处理,这样会给我们的工作带来很大的便利哦。
如何去处理数据首先要找到数据之间的联系,优惠券的折数,跟交易流水一定是一定的相关性的,这个时候就要进行图标分析啦,这个相信大家都知道,但是我们不是要找到交易流水最高的那个点对应的优惠券折数。
PS:其实这还要对比成本进行分析,数据量非常复杂,这就是数据分析师该做的事情了。
更具体一点呢,不同门店对应交易流水不同,用户使用不同折扣的优惠券会对交易流水产生更大的刺激,这也就是为什么,我的一个小小的优惠券规则,上限不到一个月就创造了数千万交易流水增收的原因了。
如果更通用的一点的话,就是取最大值/最小值问题,如果是获客那么我们就应该选取一个适合的折数来获取最大的用户。
小结Copyright © 2018 DEDE97. 织梦97 版权所有 京ICP




 这篇文章把数据讲透了(五):数据可视化(上)
这篇文章把数据讲透了(五):数据可视化(上) 数据驱动决策的10种思维
数据驱动决策的10种思维 数据的比较分析(三):假设性检验在数据比较分析中的应用
数据的比较分析(三):假设性检验在数据比较分析中的应用 技多不压身 | 产品经理需知的那些数据库基础知识
技多不压身 | 产品经理需知的那些数据库基础知识 人机耦合时代下的数据众包产业化
人机耦合时代下的数据众包产业化 2019中国网络视频市场年度分析
2019中国网络视频市场年度分析