手机版 欢迎访问人人都是自媒体网站

数据仓库是所有产品的数据中心,公司体系下的所有产品产生的所有数据最终都流向数据仓库,可以说数据仓库不产生数据,也不消费数据,只是数据的搬运工。

记得很久以前曾有一位前辈和我说过:“进来的数据是垃圾数据,出去也是垃圾数据”。
在实际环境中,往往我们一条业务线会由多个不同的系统支撑组成(例如:很多电商后端业务线都区分为库存系统、售后系统、采购系统、CRM系统等)。这些系统由于本身设计的缺陷或业务流程变更等问题,所产生的数据往往都是有缺失、冗余的,如果直接使用这些数据去进行数据分析,那最后分析出来的结论多半也不正确。
因此需要有个数据产品来对数据进行整合加工,而数据仓库就是这样一款产品。
要想了解怎么搭建数据仓库,首先需要明白数据仓库的作用:
存储数据
校准数据
整合数据
输出数据
基于以上几点,需要将数据分层次管理,每一层分工合作,对数据进行不同程度的处理,如同工厂里的流水线一般,从而确保数据的生命性、生态性。
大数据体系整体架构数据仓库并不是独立存在的一个个体,而是与整个大数据体系融为一体的——换句话说,数据仓库就像人的心脏,人只有心脏而没有其他器官是无法单独存活下来的。
大数据体系架构如图所示:
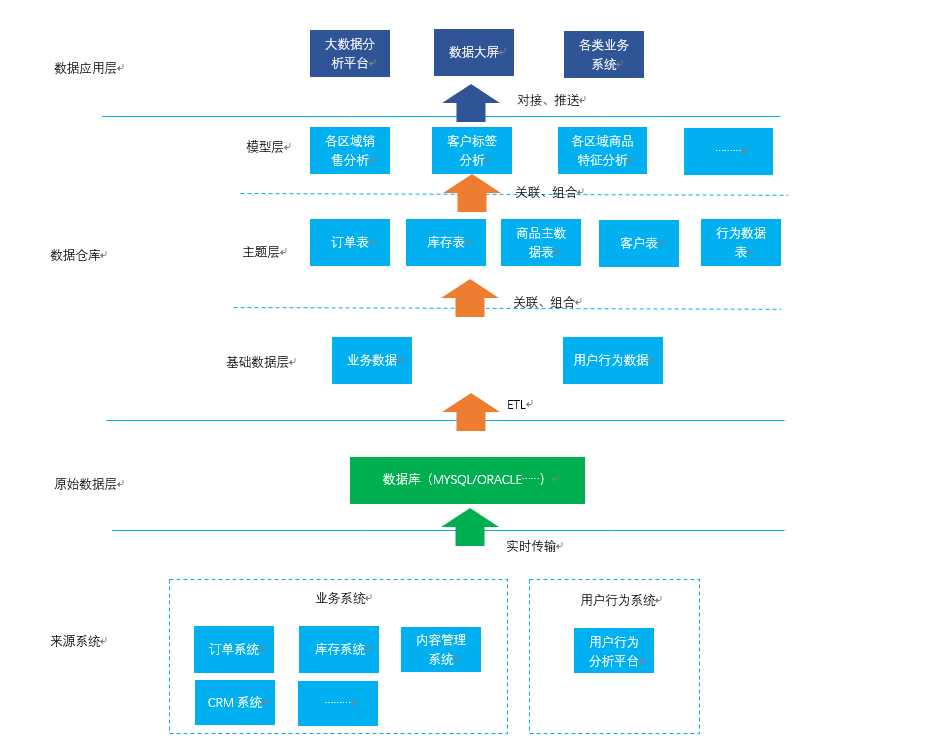
数据的来源系统,可以理解为数据的收集系统。
如图所示为基于电商业务下的大数据体系,因此数据大体可分为业务数据和用户行为数据,其来源系统更多是与电商业务相关的后端订单、库存等业务系统以及前端商城带来的用户行为数据。
原始数据层顾名思义,即存放从来源系统过来的原始数据,所谓原始数据——即未经过任何加工处理的数据。
这一层次咋看之下有点多余,但实际上是有所考量的:
1)将数据仓库与业务系统分隔开
数据仓库的数据,实时性要求不高,而准确性、清洁型必须较高,因此清洗的脚本繁多。如果每条数据都实时传送到数据仓库的话,那脚本执行的频率将非常高,所占用的系统资源也随之增加。
2)分担业务系统的报表任务
总所周知,搭建大数据体系架构所使用的硬件资源是相对较高的,而业务系统往往只是支撑业务持续开展,从性能上往往无法支撑大数据量报表的导出。因此,原始数据层可以承载此项功能,业务系统数据传输的实时性也保证了从原始数据层导出的数据符合业务人员对报表实时性的需要。
数据仓库一般来说,数据仓库可区分为三层:基础数据层、主题层、模型层
基础数据层原始数据层以天为时间周期,将每天的数据传输到数据仓库,数据仓库通过ETL(抽取、转化、加载)的方式,将数据按照设定的数据表格式存储好,形成基础数据层的数据。
何谓ETL呢?
ETL即:Extra、Transfer、Load——简单来说,即数据清洗。先将数据抽取出来,将冗余数据,错误数据,有歧义的数据按照既定的规则进行删减、填充、修改,再填充入已设定好的表结构的数据库表中。
举个栗子:
从订单系统过来的订单数据上,客户名称多种多样,相同一个客户,有大写的名称、小写的名称、有些订单甚至没有客户的相关信息(这当然是业务系统本身的历史遗留问题导致的)。此时,作为数据产品经理必须要了解这些数据的“坑”,并且和对应业务系统的产品经理共同商讨如何处理这批数据,确定好清洗逻辑(例如:所有名称统一转化为小写,如果客户名称、地址、电话号码都是同一个的,归为同一个客户),程序猿们根据数据产品经理的清洗规则写好脚本进行清洗。
主题层数据清洗就像打扫卫生一样,将不要的东西扔掉,将破旧的东西擦拭干净,但并不代表数据是完整的。
主题层的构建相对复杂,搭建的规则主要是看未来的需要以及产品经理对业务的理解。
举个栗子:
题主所在的公司是一家大型零售分销公司,因此往往有一张订单卖给零售商,零售商再下一张订单给零售店,零售单再下一张订单给终端用户。此时,每一级订单是断层,且来源于不同的系统的,因此每一级订单的表结构完全不同。
这样导致的结果是:无法从全链条上看到每一个商品在渠道中的流转,也无法实时跟踪到每个商品的具体转化效率。所以,需要把每一级的订单按照主题分门别类(一级订单、二级订单、三级订单),并且建立一种关联关系,使这三者能串联起来,形成一整个渠道流程。
模型层数据来到模型层,也就意味着他们最终要成为“炮弹”,发射到数据分析平台了,因此模型层的最主要作用是:将主题数据组合成数据分析模型。
Copyright © 2018 DEDE97. 织梦97 版权所有 京ICP




 这篇文章把数据讲透了(五):数据可视化(上)
这篇文章把数据讲透了(五):数据可视化(上) 数据驱动决策的10种思维
数据驱动决策的10种思维 数据的比较分析(三):假设性检验在数据比较分析中的应用
数据的比较分析(三):假设性检验在数据比较分析中的应用 技多不压身 | 产品经理需知的那些数据库基础知识
技多不压身 | 产品经理需知的那些数据库基础知识 人机耦合时代下的数据众包产业化
人机耦合时代下的数据众包产业化 2019中国网络视频市场年度分析
2019中国网络视频市场年度分析