手机版 欢迎访问人人都是自媒体网站


笔者最近在梳理自己的文本挖掘知识结构,借助gensim、sklearn、keras等库的文档做了些扩充,希望在梳理自身知识体系的同时也能对想学习文本挖掘的朋友有一点帮助,这是笔者写该系列的初衷。
本文会介绍几个在使用gensim进行文本挖掘所需了解的基本概念和术语,并提供一些简单的用法示例。
在更高层次上,gensim是一种通过检查词汇模式(或更高级别的结构,如语句或文档)来发现文档语义结构(Semantic Structure)的工具。
gensim通过语料库——一组文本文档,并在语料库中生成文本的向量表示(Vector Representation of the Text)来实现这一点。 然后,文本的向量表示可用于训练模型——它是用于创建不同的文本数据(蕴含语义)表示的算法。
这三个概念是理解gensim如何工作的关键,所以让我们花一点时间来解释它们的含义。与此同时,我们将通过一个简单的例子来说明每个概念。
一 、语料(Corpus)一个语料库是数字文档的集合(A Collection of Digital Documents)。 这个集合是gensim的输入,它将从中推断文档的结构或主题。从语料库中推断出的潜在结构(Latent Structure)可用于将主题分配给先前不存在于仅用于训练的语料库中的新文档。 出于这个原因,我们也将此集合称为训练语料库(Training Corpus)。
这个过程不需要人工干预(比如手动给文档打标签)——因为主题分类是无监督的(Unsupervised)(https://en.wikipedia.org/wiki/Unsupervised_learning)。
对于笔者用于示例的语料库,有12个文档,每个文档只有一个语句:
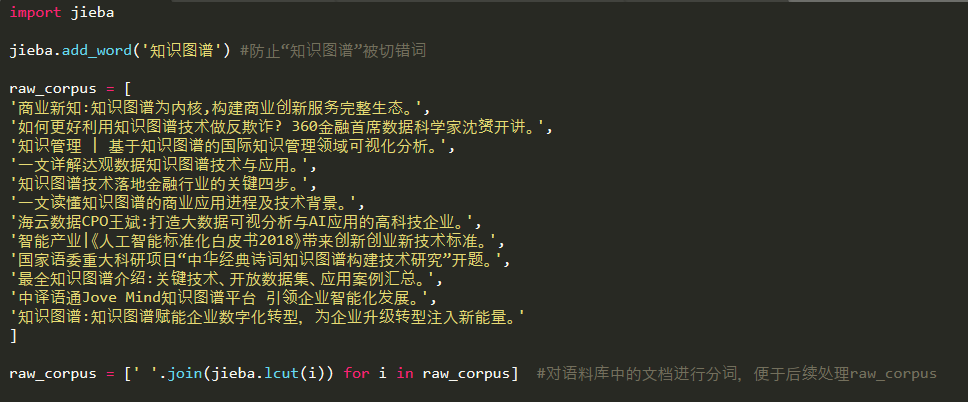

这只是一个很小的语料库,其实你可以用其他的语料库进行替代,比如:微信上的文章、微博博文,或者新闻标题等。
收集语料库之后,通常会进行一系列的文本预处理。 作为示例,为了简洁起见,笔者仅删除语料库中的停用词和在语料库中只出现一次的词汇。 在此过程中,笔者将进行分词操作,将文档分解为由词汇组成的列表(在本例中使用空格作为分隔符)。
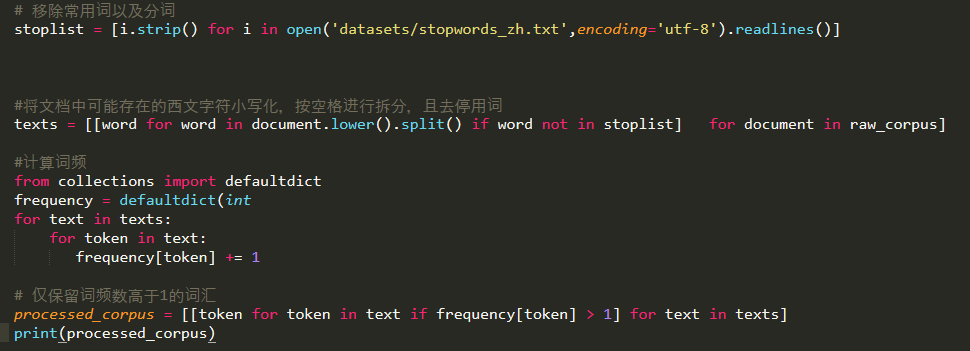
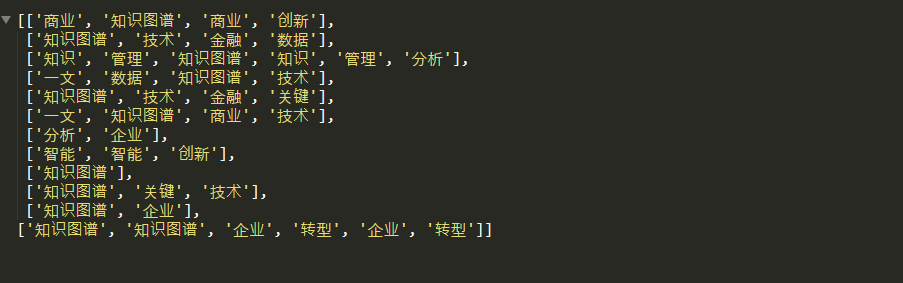
在继续之前,笔者希望将语料库中的每个词汇与唯一的整数ID相关联。 我们可以使用gensim.corpora.Dictionary这个类来完成,这个词典定义了笔者之前预处理后的语料中的词汇。
from gensim import corpora
dictionary = corpora.Dictionary(processed_corpus)
print(dictionary)
Dictionary(14 unique tokens: [‘创新’, ‘商业’, ‘知识图谱’, ‘技术’, ‘数据’]…)
因为笔者给定的语料较小, 只有14个不同的词汇在这个 Dictionary中。 对于较大的语料库,词典中会包含成千上万的词汇,数量庞大。
二 、 向量空间(Vector Space)为了推断语料库中的潜在结构(Latent Structure),我们需要一种可用于数学操作(比如,加减乘除等运算)的文档表示方法。一种方法是将每个文档表示为向量,有各种用于创建文档的向量表示的方法,其中一个简单的方法是词袋模型(Bag-of-Words Model)。
在词袋模型下,每个文档由包含字典中每个单词的频率计数的向量表示。例如:给定一个包含词汇[‘咖啡’,’牛奶’,’糖果’,’勺子’]的字典,那么,一个由字符串’咖啡 牛奶 糖果 勺子’组成的文档可以用向量表示为[2 ,1,0,0],其中向量的元素(按顺序)对应文档中出现的“咖啡”,“牛奶”,“糖”和“勺子”。向量的长度是字典中的词汇数。词袋模型的一个主要特性是它完全忽略了编码文档(the Encoded Document )中的词汇顺序,这就是词袋模型的由来。
我们处理过的语料库中有14个不同的词汇,这意味着语料库中的每个文档将由这个14维向量的词袋模型来表示,我们可以使用字典将分词后的文档转换为14维向量。由此,我们可以看到这些ID对应的词汇:print(dictionary.token2id)
{‘创新’: 0, ‘商业’: 1, ‘知识图谱’: 2, ‘技术’: 3, ‘数据’: 4, ‘金融’: 5, ‘分析’: 6, ‘知识’: 7, ‘管理’: 8, ‘一文’: 9, ‘关键’: 10, ‘企业’: 11, ‘智能’: 12, ‘转型’: 13}
Copyright © 2018 DEDE97. 织梦97 版权所有 京ICP




 这篇文章把数据讲透了(五):数据可视化(上)
这篇文章把数据讲透了(五):数据可视化(上) 数据驱动决策的10种思维
数据驱动决策的10种思维 数据的比较分析(三):假设性检验在数据比较分析中的应用
数据的比较分析(三):假设性检验在数据比较分析中的应用 技多不压身 | 产品经理需知的那些数据库基础知识
技多不压身 | 产品经理需知的那些数据库基础知识 人机耦合时代下的数据众包产业化
人机耦合时代下的数据众包产业化 2019中国网络视频市场年度分析
2019中国网络视频市场年度分析